En los últimos años, la elección de nombres sin género se ha vuelto cada vez más común en diferentes culturas. Estos nombres permiten desafiar las convenciones tradicionales y promover la igualdad de género. En esta publicación, exploraremos los nombres sin género utilizados en los nacimientos de la ciudad de Nantes, en Francia, desde el año 2001 hasta el 2022. Analizaremos una base de datos de data.nantesmetropole.fr que contiene los nombres de niños y niñas nacidos en ese periodo, identificando aquellos nombres que no tienen una asignación específica de género. Acompáñanos en este recorrido por la diversidad de nombres y descubre qué nombres sin género han sido populares en Nantes durante más de dos décadas.
Análisis ETL:
Utilizando una base de datos que recopila información sobre los nombres de los recién nacidos en Nantes, creamos un ETL(Extract, Transform, Load) en Python para analizar y visualizar los datos presentados en formato .CSV, donde a partir de la librería Pandas capturamos la información inicial que nos presenta el conjunto: Tipos y cantidad de variables, número de registros del dataset y revisión de datos faltantes.
Utilizaremos las bibliotecas pandas, matplotlib y plotly para realizar el análisis y la visualización de datos. Asegúrate de tener instaladas estas bibliotecas antes de ejecutar el código. Puedes instalarlas utilizando el administrador de paquetes pip. Por ejemplo, ejecuta pip install pandas matplotlib plotly en tu entorno para instalarlas.
import pandas as pd
import matplotlib.pyplot as plt
import plotly.express as px
# Extracción de datos
data = pd.read_csv('nantes_prenoms.csv')Exploración inicial del conjunto de datos:
Después de importar los datos, extraemos su información básica con Pandas: conteo de registros, # de columnas y tipos de variable.
data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 6037 entries, 0 to 6036
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Commune concernée 6037 non-null object
1 Code INSEE 6037 non-null int64
2 Sexe relatif au prénom 6037 non-null object
3 Prénom 6037 non-null object
4 Nombre d'occurrences 6037 non-null int64
5 Année 6037 non-null int64
dtypes: int64(3), object(3)
memory usage: 283.1+ KB
NoneRenombramos las columnas a utilizar para eliminar acentos, espacios y unificar el uso de mayúsculas y minúsculas:
# Transformación de datos
data = data.rename(columns={'Sexe relatif au prénom':'sexe','Prénom':'prenom',"Nombre d'occurrences":'naissances', 'Année':'annee'})Validamos si el dataframe contiene datos nulos:
data.isnull().sum()
Commune concernée 0
Code INSEE 0
sexe 0
prenom 0
naissances 0
annee 0
dtype: int64Descubriendo los nombres sin género en Nantes:
A lo largo de los años, hemos observado una creciente tendencia hacia la elección de nombres sin género en Nantes. Desde el año 2001 hasta el 2022, se han registrado varios nombres que no están asociados de manera exclusiva con un género específico. Algunos de estos nombres sin género han ganado popularidad y se han convertido en opciones populares para padres y madres que desean que sus hijos tengan una identidad de género no binaria.
Mediante el agrupamiento, filtros y conteos finales, hemos identificado los nombres que tienen una asignación de género femenina y masculina. Podemos presumir que estos nombres son elegidos por padres y madres que buscan romper con las normas tradicionales y permitir que sus hijos elijan libremente su identidad de género en el futuro.
# Análisis y visualización de datos
# Filtrar nombres sin género (aparecen tanto en sexo masculino como femenino)
names_without_gender = data.groupby('nombre').filter(lambda x: x['Sexo'].nunique() == 2)
# Contar ocurrencias de nombres sin género
names_count = names_without_gender.groupby('nombre')['Nacimientos'].sum().reset_index()
# Gráfico de barras de nombres sin género
fig_names_without_gender = px.bar(names_count, x='nombre', y='Nacimientos', title='Nombres Sin Género Utilizados')
fig_names_without_gender.update_layout(xaxis_title='Nombres', yaxis_title='Cantidad de Nacimientos')
fig_names_without_gender.show()
En este código, primero leemos el archivo CSV y almacenamos los datos en el dataframe data. Luego, filtramos los nombres que aparecen tanto en sexo masculino como femenino utilizando la función groupby() junto con filter(). A continuación, contamos las ocurrencias de cada nombre sin género utilizando groupby() y sum(). Por último, creamos un gráfico de barras utilizando px.bar() de Plotly Express, donde el eje x muestra los nombres y el eje y muestra la cantidad de nacimientos asociados a cada nombre. Cada barra tiene un color único para facilitar la identificación y destacar la diversidad de nombres sin género utilizados en la ciudad.
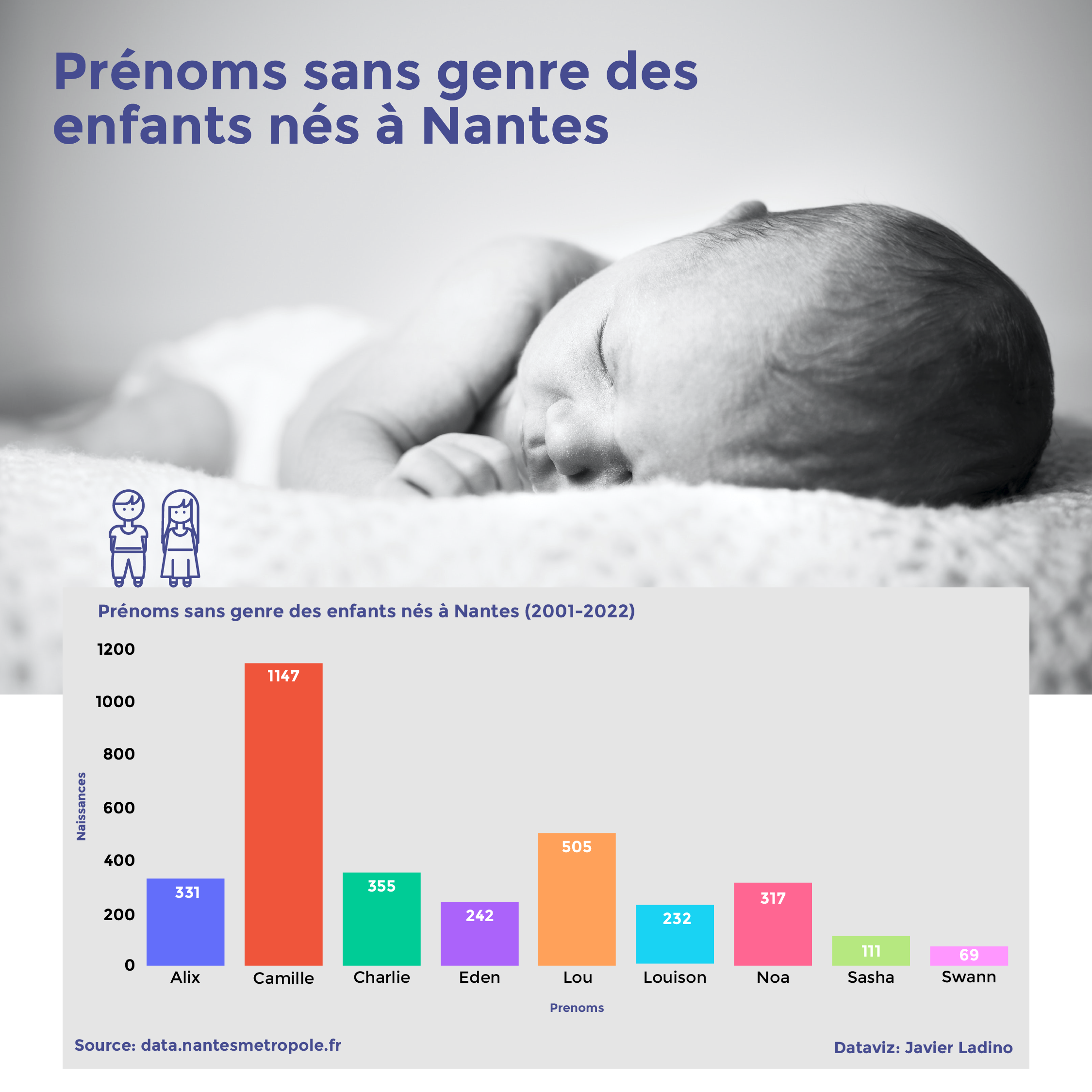
# Nombres utilizados en ambos sexos
common_names_both_genders2 = data.groupby('prenom')['sexe'].nunique()
common_names_both_genders2 = common_names_both_genders2[common_names_both_genders2 == 2].index
common_names_both_genders2
9 resultados: ['Alix', 'Camille', 'Charlie', 'Eden', 'Lou', 'Louison', 'Noa', 'Sasha', 'Swann']
Cumpliendo nuestro objetivo inicial de obtener los 9 nombres más comunes utilizados para ambos sexos en Nantes, podemos retomar la exploración del dataframe y solucionar algunas preguntas básicas que nos ayuden a realizar su análisis.
Cuál es el total de registros ?
El dataframe cuenta con 6037 registros de nacimiento entre el 2001 y el 2022.
data.shape
(6037, 6)Cuántos nombres únicos existen ?
El dataframe cuenta con 731 nombres únicos utilizados.
data['prenom'].nunique()
731Si quieres ver el listado completo ejecuta:
data['prenom'].unique()Visualizamos con Plotly la cantidad de nombres únicos por año, siendo el 2003 el más bajo con 183 nacimientos y el 2022 (año en pandemia) con 316 nacimientos.

Cuál es la distribución total por género ?
Entre el año 2001 y 2022, nacieron más niños (3110) que niñas (2927) en la ciudad de Nantes.
data['sexe'].value_counts()
M 3110
F 2927
Name: sexe, dtype: int64Podemos generar como visualización una gráfica de pie:
gender_distribution = data['sexe'].value_counts()
fig_gender = px.pie(names=gender_distribution.index, values=gender_distribution.values, title='Distribución de género de los niños')
fig_gender.show()
Visualizar la distribución de sexo por cada año:
fig_gender_year = px.histogram(data, x='annee', color='sexe', text_auto=True, title='Répartition des sexes par année')
fig_gender_year.show()
Cuáles son los nombres más utilizados del conjunto de datos ?
De los 731 nombres únicos presentes en el dataframe, filtramos los 10 primeros lugares según la cantidad de nacimientos. También los visualizamos según su género para nuestro objetivo principal de identificar los nombres no binarios, resaltando «Camille», nombre sin genero ubicado en el segundo lugar del ranking con 1147 registros después de «Louise», nombre femenino que ocupa el primer lugar con 1158 registros.
# Agrupar por nombre y sexo y contar la cantidad de ocurrencias
names_count = data.groupby(['prenom', 'sexe'])['naissances'].sum().reset_index()
# Filtrar solo los nombres más utilizados
top_names = names_count.groupby('prenom')['naissances'].sum().nlargest(10).index
# Filtrar los datos solo para los nombres más utilizados
top_names_data = names_count[names_count['prenom'].isin(top_names)]
prenom sexe naissances
80 Arthur M 1143
121 Camille F 890
122 Camille M 257
211 Emma F 1102
281 Hugo M 1024
327 Jules M 1037
402 Louis M 1104
404 Louise F 1158
415 Lucas M 1122
436 Léo M 977
452 Manon F 975
# Gráfico de barras diferenciado por color según el sexo
fig_top_names = px.bar(top_names_data, x='prenom', y='naissances', color='sexe', text_auto=True, title='Prénoms les plus utilisés (différenciés par sexe)')
fig_top_names.update_layout(xaxis_title='Prénoms', yaxis_title='Nombre de naissances')
fig_top_names.show()
Cuáles son los nombres más utilizados por cada año ?
Podemos visualizar el nombre que ocupa la primera posición para cada año del dataframe, donde «Camille» domina su presencia en 6 años diferentes, seguido por «Charlie» (5 años), «Louison» (4 años) y «Noa» (3 años).
popular_names = data.groupby('annee')['prenom'].agg(lambda x: x.value_counts().index[0])
fig_popular_names = px.bar(x=popular_names.index, y=popular_names.values, text_auto=True, color=popular_names, color_continuous_scale = 'viridis', title='Prénom le plus populaire par an')
fig_popular_names.show()
Porcentaje de nombres con género a lo largo del tiempo
Mediante un gráfico de barras apiladas mostramos el porcentaje de nombres por género a lo largo del tiempo, utilizando el color azul para el género masculino «M» y el color naranja para el género femenino «F»:

Enlace a la visualización interactiva en Plotly
En este código, después de calcular el porcentaje de nombres de pila por género y año, asignamos colores a los géneros utilizando la asignación de colores. A continuación, creamos un gráfico de barras apiladas utilizando go.Bar() de Plotly Graph Objects. Iteramos sobre los géneros y añadimos una barra para cada género con diferentes colores. Por último, actualizamos el diseño del gráfico con un título, los títulos de los ejes y mostramos el gráfico generado por Plotly.
Ejecuta el código y podrás interactuar con el gráfico de barras apiladas que muestra el porcentaje de nombres de pila por género a lo largo del tiempo.
# Calculer le pourcentage de prénoms par sexe et par année
percentage_data = data.groupby(['annee', 'sexe']).size() / data.groupby('annee').size() * 100
percentage_data = percentage_data.reset_index(name='percentage')
# Attribuer des couleurs aux sexes
color_map = {'M': 'blue', 'F': 'orange'}
percentage_data['Color'] = percentage_data['sexe'].map(color_map)
# Créer un diagramme à barres empilées du pourcentage de prénoms par sexe au fil du temps
fig = go.Figure()
for sexe in ['M', 'F']:
fig.add_trace(go.Bar(
x=percentage_data[percentage_data['sexe'] == sexe]['annee'],
y=percentage_data[percentage_data['sexe'] == sexe]['pourcentage'],
name=sexe,
marker_color=color_map[sexe]
))
fig.update_layout(
title='Pourcentage de noms de piles par sexe à Nantes',
xaxis_title='Année',
yaxis_title='Pourcentage',
barmode='stack'
)
fig.show()Tendencia de nombres sin género para los próximos años
Gracias al comentario de Line Ton That, donde se preguntaba por el impacto de Camille en todo esto, si su nombre ya no estaría tan de moda en los próximos años, o si veremos la misma tendencia en los nombres sin género : utilicé la biblioteca scikit-learn (sklearn) para calcular la tendencia de los nombres que aparecen en ambos sexos en función del número total de nacimientos por nombre y año. Luego, visualiza la tendencia de estos nombres utilizando un gráfico de barras con la biblioteca Plotly Express (px).

Enlace a la visualización interactiva en Plotly
Aquí se explica el flujo de ejecución del código paso a paso:
from sklearn.linear_model import LinearRegression
# Filtrar los nombres que aparecen en ambos sexos
both_sex_names = data.groupby('prenom').filter(lambda x: len(x['sexe'].unique()) == 2)
# Calcular el número total de nacimientos por nombre y año
nacimientos_por_nombre_y_año = both_sex_names.groupby(['prenom', 'annee'])['naissances'].sum().reset_index()
# Paso 3: Análisis y visualización de datos
# Crear un DataFrame con las tendencias futuras
tendencias_futuras = pd.DataFrame(columns=['prenom', 'tendencia'])
# Calcular la tendencia para cada nombre
for nombre in both_sex_names['prenom'].unique():
nombre_data = nacimientos_por_nombre_y_año[nacimientos_por_nombre_y_año['prenom'] == nombre]
# Utilizar regresión lineal para calcular la tendencia
X = nombre_data['annee'].values.reshape(-1, 1)
y = nombre_data['naissances'].values
model = LinearRegression()
model.fit(X, y)
tendencia = model.coef_[0]
tendencias_futuras = tendencias_futuras.append({'prenom': nombre, 'tendencia': tendencia}, ignore_index=True)
# Ordenar los nombres por tendencia descendente
tendencias_futuras = tendencias_futuras.sort_values(by='tendencia', ascending=False)
# Visualizar la tendencia de los nombres que utilizan ambos géneros
fig = px.bar(tendencias_futuras, x='prenom', y='tendencia', labels={'tendencia': 'Tendencia'},
title='Tendencia de Nombres que Utilizan Ambos Géneros en los Próximos Años')
fig.update_layout(xaxis_title='Nombre', yaxis_title='Tendencia')
fig.show()En resumen, este código filtra los nombres que aparecen en ambos sexos, calcula la tendencia utilizando la regresión lineal y visualiza la tendencia de los nombres utilizando un gráfico de barras. Esto permite obtener información sobre los nombres que tienen una tendencia creciente o decreciente en términos de su popularidad a lo largo de los años.
Luego de realizar la regresión lineal observamos una tendencia decreciente del nombre «Camille» para los próximos años, y un aumento del nombre «Charlie» frente a los otros nombres sin género.
Conclusión:
El análisis de los nombres sin género utilizados en los nacimientos de Nantes nos muestra la evolución y aceptación de la diversidad de género en la sociedad. Padres y madres están optando por nombres que no están restringidos a una única identidad de género, brindando a sus hijos la libertad de explorar y definir su propia identidad en el futuro. Esta tendencia refleja una mayor apertura y aceptación hacia la diversidad en la sociedad, así como el deseo de fomentar la igualdad de género desde el inicio de la vida.
Resulta interesante, que al comparar los nombres más populares por año, estén presentes 5 de los 9 nombres sin género encontrados al inicio de la exploración (Camille, Charlie, Louison, Noa y Sasha). Esto determina la firme decisión que tomaron sus padres al nombrar a sus hijos e hijas de una manera no binaria, sea por tendencia o un fenómeno adaptativo para las nuevas generaciones.
Seguramente estos resultados cambiarán según los datos de la ciudad y el país, de manera que si alguién quisiera compartir sus resultados para compararlos con los de Nantes, no dude en ponerse en contacto para seguir aprendiendo de manera colaborativa.
Referencias: