Manual technology monitoring means 3–4 hours per week of reading, sorting, and summarizing. Information pours in from everywhere, in different formats, without prioritization. How can we turn it into a useful collective resource without spending so much time on it?
Chosen Problem Statement: How does the FinOps + Green IT + Data Sovereignty equation reconfigure Cloud / On-Premise / Hybrid architecture choices for businesses in 2026?
System Architecture
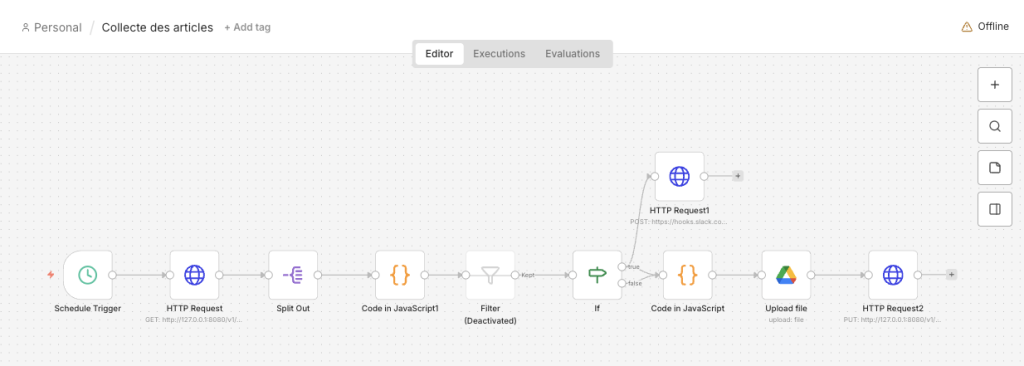
n8n Workflow 1 Canvas — Automatic collection pipeline every 2 hours
Infrastructure: Self-hosted VM on Proxmox
Rather than paying for a SaaS, I deployed all the tools on an existing VM:
| Component | Version | Role |
|---|---|---|
| Proxmox | Hypervisor | On-premise VM |
| Debian 12 | OS | 2 vCPU · 2 GB RAM · 20 GB |
| PostgreSQL 15 | Port 5432 | Miniflux Database |
| Miniflux | Port 8080 | RSS Aggregator |
| n8n | Port 5678 | Workflow Orchestrator |
| Nginx | Port 80 | Reverse proxy |
Access: SSH tunnel from the client station — no ports exposed to the Internet.
Monthly Cost: €0 — infrastructure already existed, tools are 100% open source.
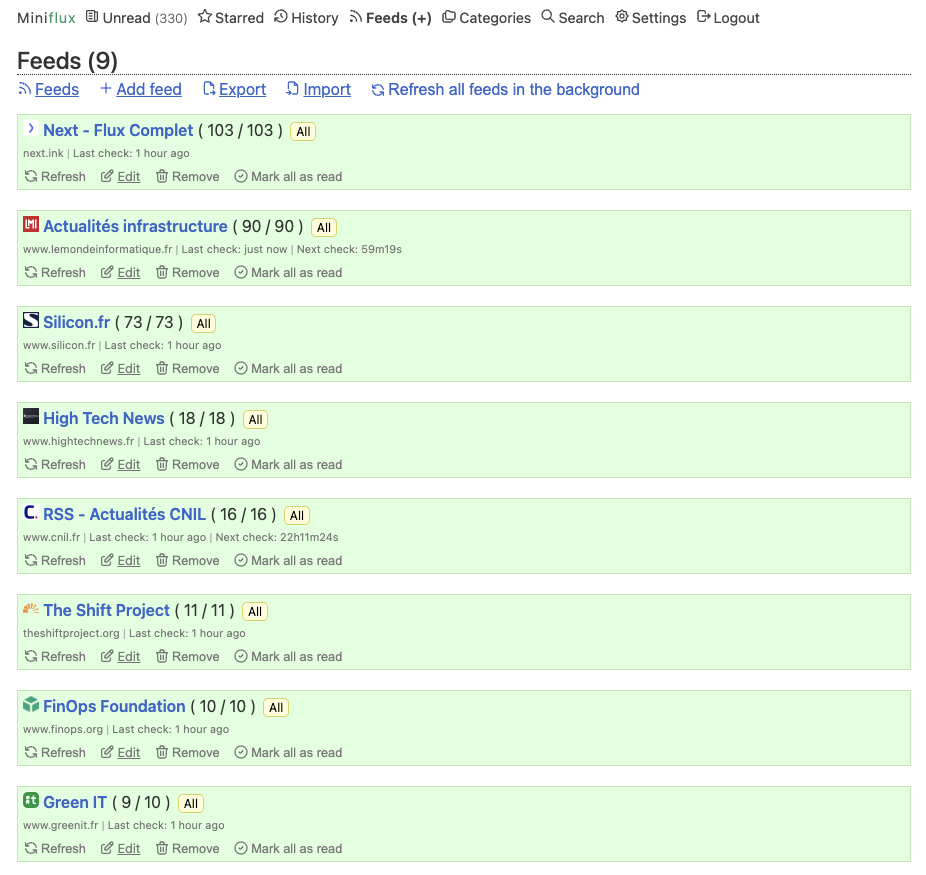
Miniflux Interface — 10+ active RSS feeds organized by topic
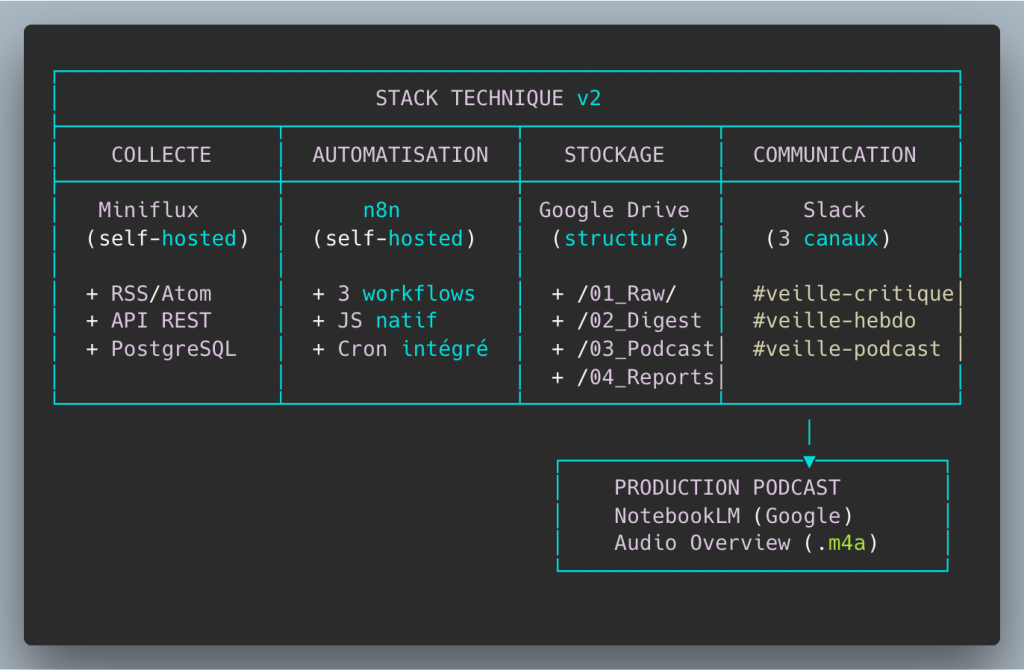
The 3 n8n Workflows (ETL Pipeline)
Workflow 1 — Continuous Collection (Every 2h)
Schedule Trigger (2h)
→ HTTP GET /v1/entries?status=unread ← Miniflux REST API
→ Split Out ← Separate articles
→ JS Code: keyword filtering ← FinOps / Green IT / Sovereignty
→ JS Code: Markdown construction ← Structured format
→ Google Drive: Upload /01_Raw/ ← Storage
→ HTTP PUT /v1/entries ← Mark as read
→ Slack Webhook #veille-critique ← Real-time alerts

n8n Code Node — Keyword filtering logic (FR + EN) in JavaScript
Workflow 2 — Weekly Digest (Monday 08:00 AM)
Schedule Trigger (Monday 08h)
→ JS Code: timestamp -7d, week number
→ HTTP GET /v1/entries?after=TIMESTAMP ← Articles from the last 7 days
→ JS Code: aggregation by topic ← FinOps / Green IT / Sovereignty
→ Google Drive: Upload /02_Digest/ ← Structured Markdown digest
→ Slack Webhook #veille-hebdo ← Summary + Drive link
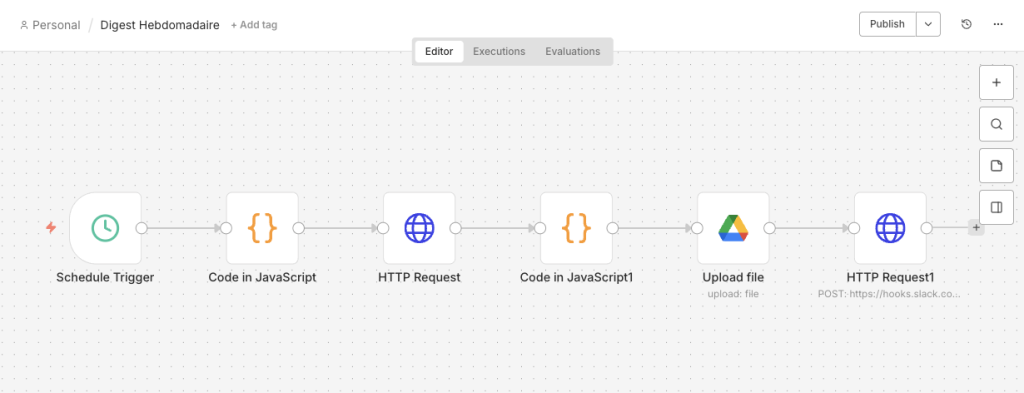
Workflow 2 Canvas — Automatic weekly digest generation
Workflow 3 — Podcast Notification (Drive File Trigger)
Google Drive Trigger ← New file in /03_Podcast/
→ Slack Webhook #veille-podcast ← Automatic listening link
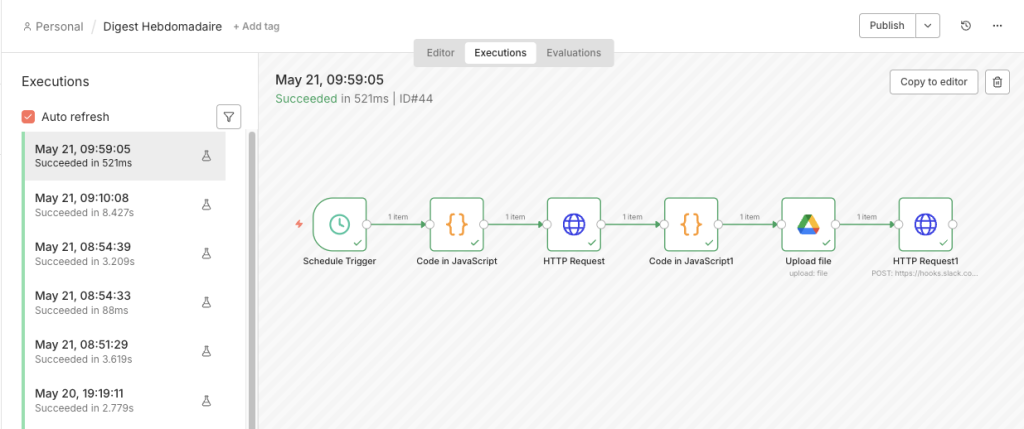
n8n Execution History — Pipeline active 24/7
Collection: Miniflux
Miniflux automatically aggregates 10+ RSS feeds every hour. Articles are stored in PostgreSQL and exposed via a REST API consumed by n8n.
Active Sources by Topic:
| FinOps | Green IT | Sovereignty |
|---|---|---|
| FinOps Foundation | GreenIT.fr | CNIL |
| Le Monde Informatique | The Shift Project | Numerama |
| Silicon.fr | ADEME | Next.ink |
| The New Stack | Next.ink | Silicon.fr |
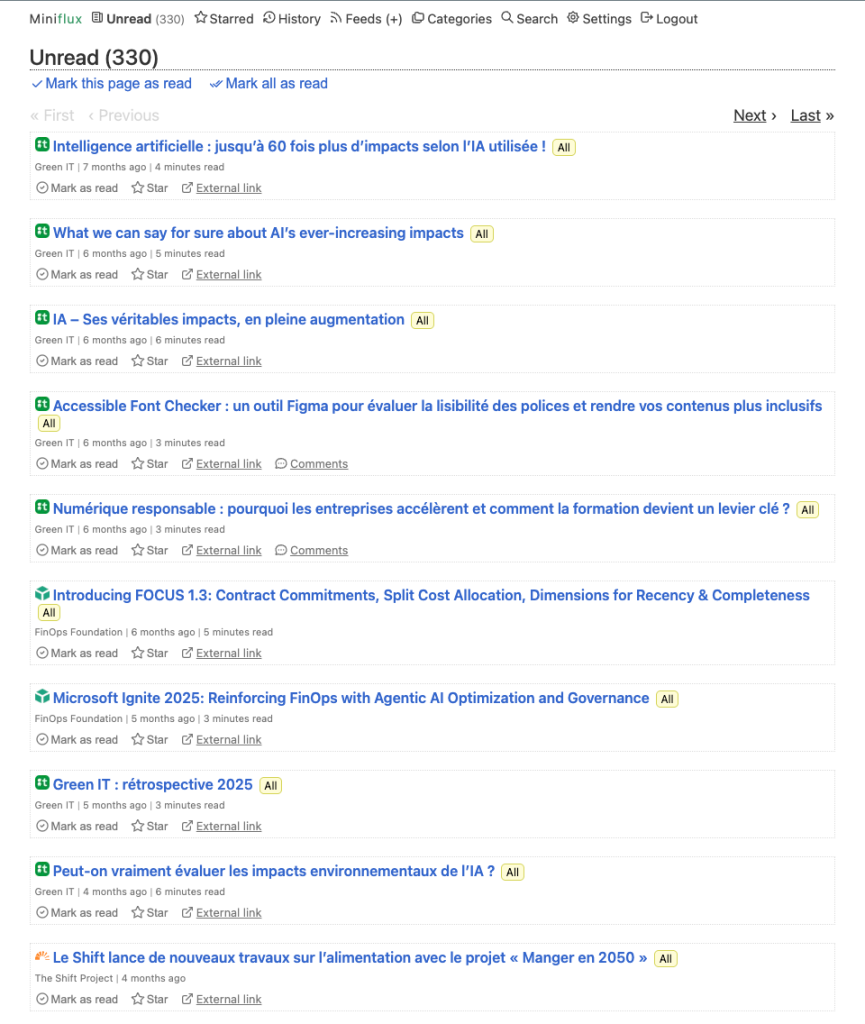
List of unread articles in Miniflux — weekly collection volume
Structured Storage: Google Drive
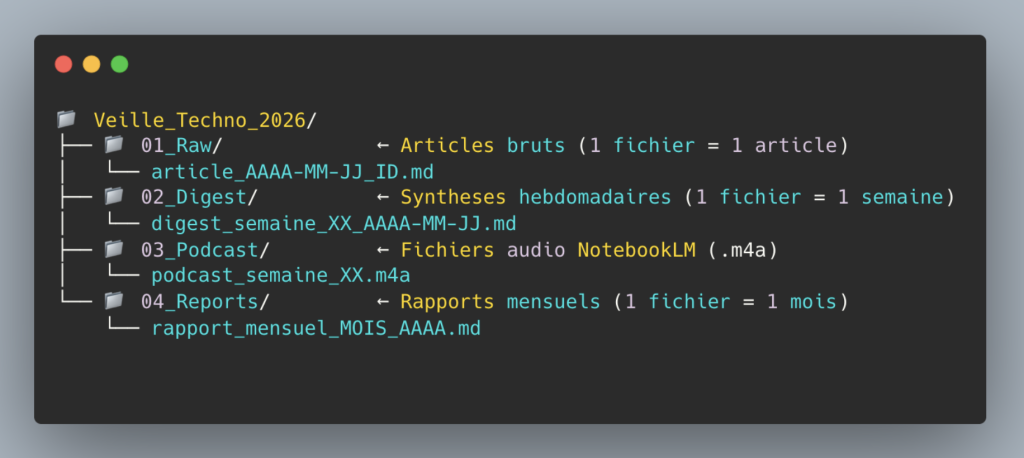
Information is organized according to 4 processing tiers:
Google Drive Storage Structure — 4 information processing tiers
Folder /01_Raw — automatically collected articles (naming: article_YYYY-MM-DD_ID.md)
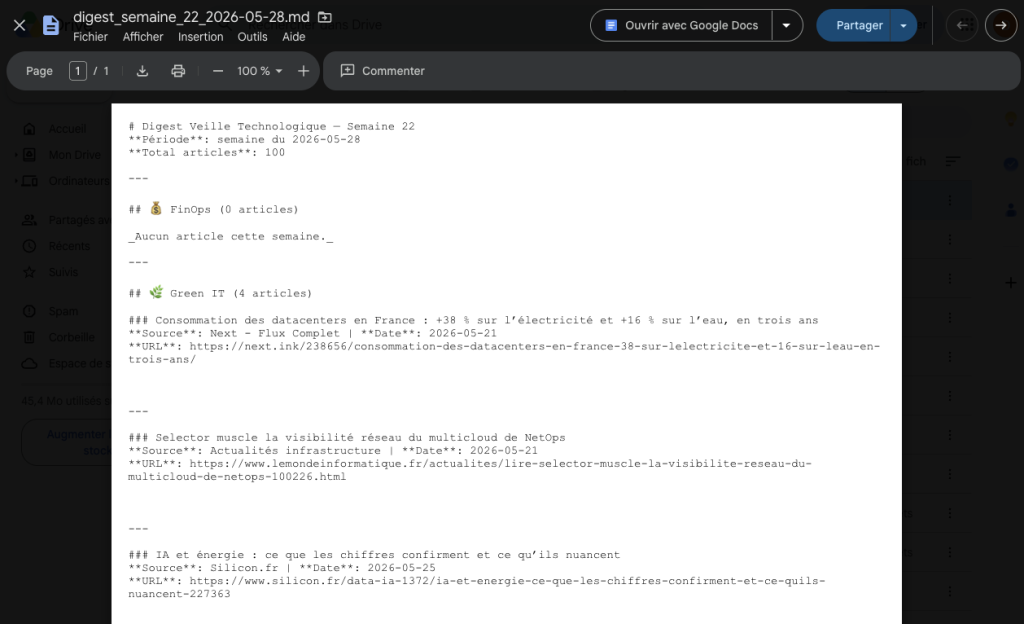
Weekly Digest — automatic summary by topic with article counters
Distribution: Slack 3 Channels
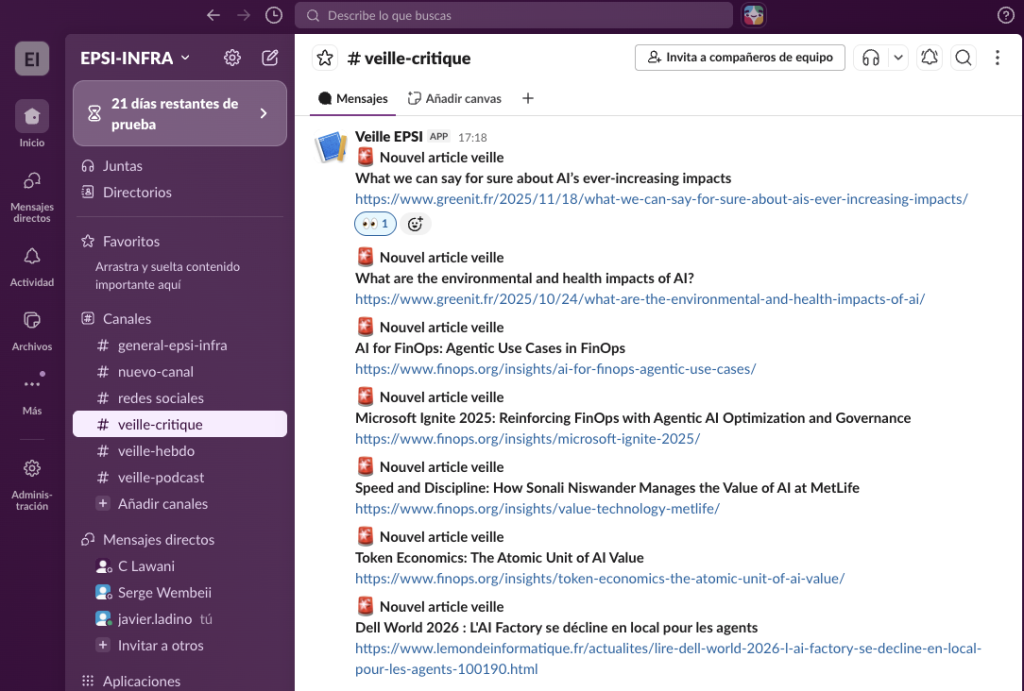
#veille-critique — real-time alerts on high-value topical articles
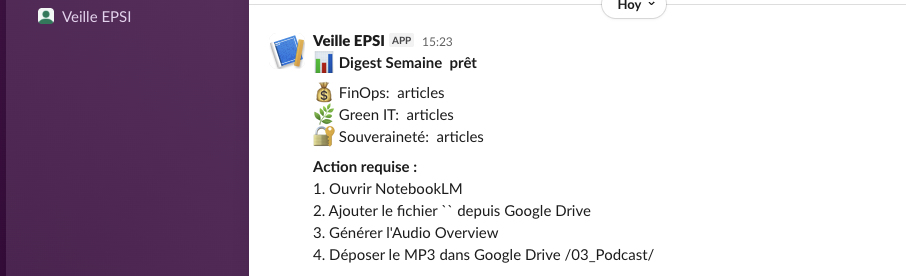
#veille-hebdo — structured digest sent every Monday at 08:00 AM with Google Drive link

#veille-podcast — automatic notification when a new audio file is detected
AI Podcast: NotebookLM
Every week, the Markdown digest is imported into NotebookLM to generate a 15–20 minute Audio Overview.
Prompt used:
Generate a technology monitoring podcast in French.
Themes: FinOps, Green IT, Data Sovereignty.
Tone professional yet accessible.
Structure: introduction, 3 topical segments, trend of the week.
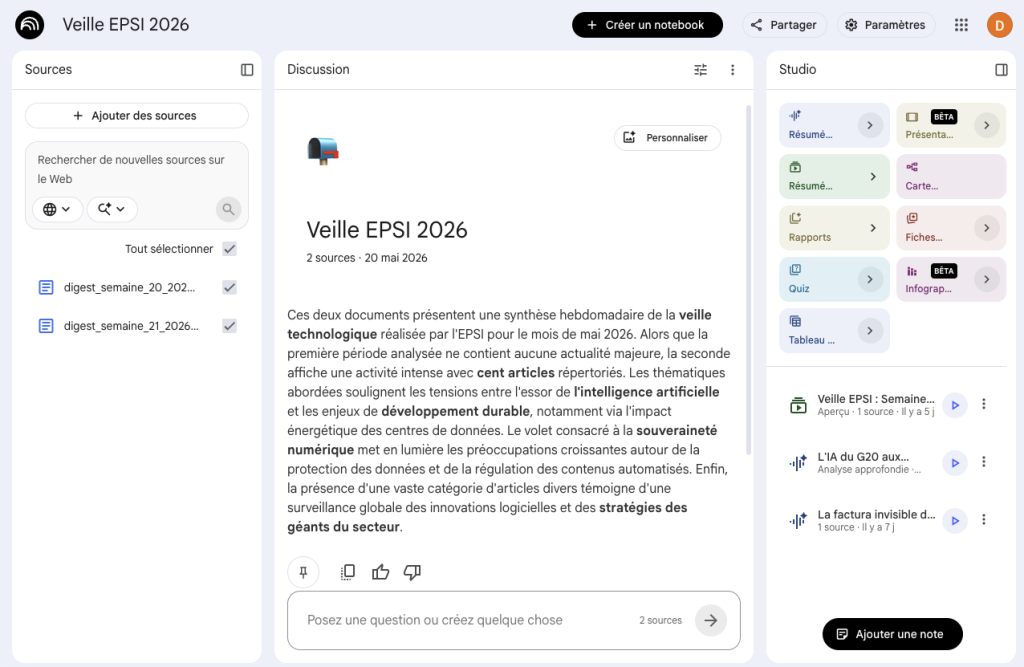
NotebookLM — “Veille EPSI 2026” Notebook with permanent sources + weekly digest
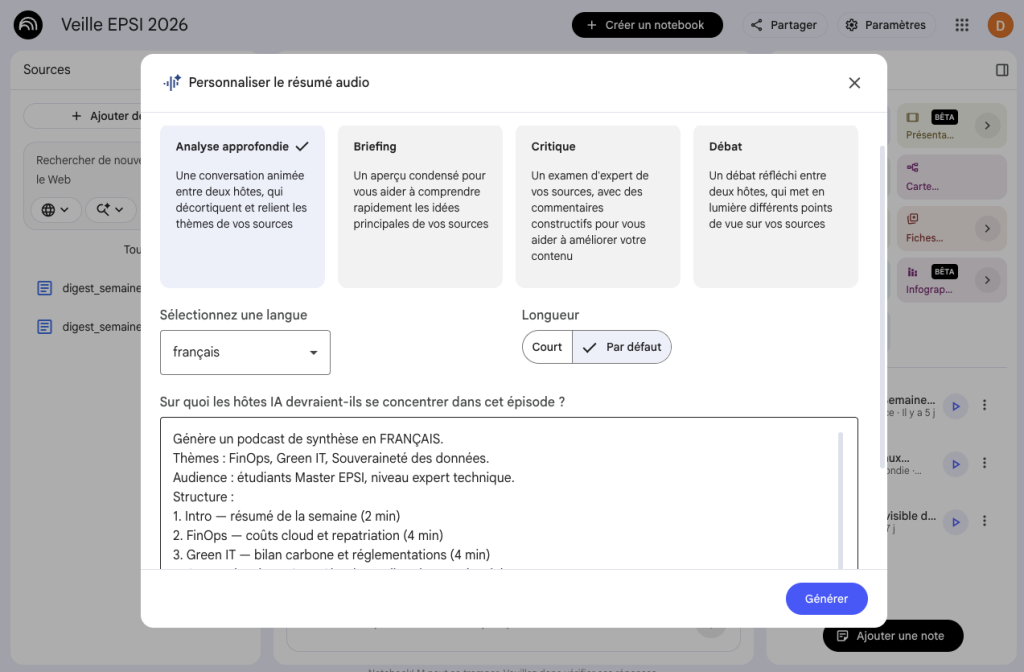
Audio Overview Interface — AI podcast generation (~10 min processing time)
Metrics & Measured Results
| Indicator | Target | Week 21 Result |
|---|---|---|
| Active RSS sources | ≥ 10 | ✅ 10+ |
| Articles collected/week | 50–100 | ✅ 98 |
| Articles categorized/week | ≥ 15 | ✅ 14 |
| Digest generated/week | 1 | ✅ Automatic |
| Podcast produced/week | 1 | ✅ ~4 min manual work |
| Monthly infrastructure cost | €0 | ✅ €0 |
Processing Funnel:
~300 raw RSS articles
→ 98 collected by Miniflux (−67%)
→ 14 categorized by n8n (−86%)
→ 1 Markdown digest
→ 1 AI podcast (15–20 min)
→ Decision intelligence
What We Learned
This project demonstrates the following skills, directly applicable in Data Engineering:
| Skill | Practical Application in This Project |
|---|---|
| Data Pipeline | 3 ETL workflows orchestrated on n8n |
| REST API Integration | Consuming the Miniflux API (GET/PUT/JSON) |
| Data Transformation | Native JavaScript: filtering, aggregating, Markdown formatting |
| On-premise Infrastructure | Debian 12 VM on Proxmox, PostgreSQL, Nginx, systemd |
| Structured Storage | 4-tier architecture in Google Drive |
| Automation | Cron jobs, Drive triggers, Slack webhooks |
| Monitoring | Weekly KPIs, n8n execution history |
| Open Source | 100% open-source stack, zero vendor lock-in |
Code & Documentation
- GitHub Repository: https://github.com/javiladino/veille_techno_2026
- Technical Documentation: architecture, workflows, KPIs, deployment guide
- Monthly Report: March 2026 available in
/reports/
This project was carried out in collaboration with Serge WEMBE II-ESSOUMBA and Cheik LAWANI