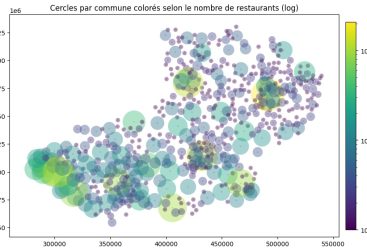
Grâce à la plateforme Air Pays de la Loire, nous explorerons la qualité de l’air pour comprendre les complexités du problème de la pollution : identifier les points chauds et corréler les niveaux avec des activités humaines spécifiques au cours de l’année 2023. Nous ferons une analyse détaillée des données de concentration de polluants enregistrées dans des stations de mesure filtrées en Loire-Atlantique. Du dioxyde d’azote aux particules PM2,5 et PM10, comprenons comment ces émissions affectent la santé et l’environnement. Rejoignez-nous dans ce voyage à travers des données révélatrices qui nous aideront à mieux comprendre les défis environnementaux et à développer des solutions pour un avenir plus propre.
Introduction
La pollution atmosphérique est un problème mondial majeur. Plus de 6000 villes dans 117 pays surveillent la qualité de l’air, mais leurs habitants respirent encore des niveaux malsains de particules fines et de dioxyde d’azote, les habitants des pays à revenu faible ou intermédiaire étant les plus exposés.

La pollution accélère le changement climatique. L’OMS estime que la pollution atmosphérique post-pandémique est associée à plus de 7 millions de décès par an. Ses conclusions soulignent l’importance de réduire l’utilisation des combustibles fossiles et de prendre d’autres mesures pour réduire les niveaux de pollution de l’air.
Savez-vous quels polluants vous respirez chaque jour ? 😷
Les agences internationales se sont concentrées sur l’analyse des types de polluants les plus courants : les concentrations de dioxyde d’azote (NO2 ), de PM2,5 et de PM10, et de dioxyde de soufre SO2.
Dioxyde d’azote (NO2 )
Le NO2 est un polluant urbain courant et un précurseur des particules et de l’ozone. Il est associé aux maladies respiratoires, en particulier à l’asthme, entraînant des symptômes respiratoires (toux, respiration sifflante ou essoufflement), des admissions à l’hôpital et des visites aux urgences.
Les oxydes d’azote sont générés par les températures élevées des processus de combustion. Dans les endroits où la circulation est intense, les véhicules à combustion interne produisent environ 60 % du total des oxydes d’azote présents dans l’atmosphère.
Les effets de ces gaz sont évidents : visibilité réduite, corrosion des matériaux, réduction de la croissance de certaines espèces végétales, etc. En outre, ils peuvent se transformer en acide nitrique qui, lorsqu’il est présent dans l’atmosphère, peut donner lieu à des pluies acides en cas de précipitations.
Les oxydes d’azote sont en grande partie responsables de la destruction de la couche d’ozone. De petites quantités de ces gaz peuvent détruire de grandes quantités d’ozone. Cette situation est aggravée par le fait qu’ils ne peuvent être éliminés de l’atmosphère que par des processus naturels, qui sont évidemment beaucoup plus lents que la production de ces gaz.
De nombreux autres gaz polluants sont libérés dans l’atmosphère, tels que les oxydes de soufre ou de carbone, ainsi que d’autres composés et métaux tels que le plomb, le cadmium, le nickel, le fer, le mercure, le chrome, le cuivre, etc. Tous contribuent par leurs effets négatifs à la dégradation de l’environnement.
PM2,5 et PM10
PM est l’abréviation de particulate matter (matière particulaire) et la valeur se réfère au diamètre des particules. Les PM2,5 ont un diamètre inférieur à 2,5 microns (μm), tandis que les PM10 ont un diamètre inférieur à 10 microns (μm). Ces deux types de particules sont plus petites que la largeur d’un cheveu humain, dont le diamètre est généralement compris entre 17 et 180 μm.
Les particules en suspension dans l’air, en particulier les PM2,5 , sont capables de pénétrer profondément dans les poumons et d’entrer dans la circulation sanguine, provoquant des impacts cardiovasculaires, cérébrovasculaires (accidents vasculaires cérébraux) et respiratoires. Il est de plus en plus évident que les particules ont un impact sur d’autres organes et provoquent également d’autres maladies. Les PM2,5 sont nocives à court terme et ont des conséquences néfastes sur les groupes vulnérables tels que les enfants et les personnes âgées. Les PM10, en revanche, sont plus nocives en cas d’exposition chronique et répétée, en particulier chez les personnes souffrant de maladies pulmonaires préexistantes.
Dioxyde de soufre SO2
Dioxyde de soufre SO2, un gaz qui provient principalement de la combustion de combustibles fossiles contenant du soufre (pétrole, combustibles solides), principalement dans le cadre de processus industriels à haute température et de la production d’électricité. Peut avoir des effets néfastes sur la santé, tels que l’irritation et l’inflammation du système respiratoire, les maladies pulmonaires et l’insuffisance pulmonaire, l’altération du métabolisme des protéines, les maux de tête ou l’anxiété, sur la biodiversité, les sols, les écosystèmes aquatiques et forestiers (peut causer des dommages à la végétation, dégradation de la chlorophylle, réduction de la photosynthèse et perte conséquente d’espèces) et même sur les bâtiments, par des processus d’acidification, car une fois émis, il réagit avec la vapeur d’eau et d’autres éléments présents dans l’atmosphère, de sorte que son oxydation dans l’air conduit à la formation d’acide sulfurique.
Tous ces éléments contribuent, par leurs effets négatifs, à la santé des personnes et de la planète elle-même. Par conséquent, toutes les mesures visant à réduire les émissions, à perfectionner, à améliorer et à optimiser les moteurs à combustion interne, ou même à restreindre la circulation dans les villes, sont positives pour notre avenir. À partir de l’ensemble des données obtenues sur la plateforme www.data.airpl.org, nous pouvons identifier les lieux les plus pollués en fonction de leur type et de l’activité humaine qui les génère.
Origine des données 📁
Les données utilisées sur les concentrations de polluants ont été enregistrées dans les stations de mesure d’Air Pays de la Loire au cours de l’année 2023.

Selon la description du site internet : https://data.airpl.org/dataset/mesures, pour obtenir ces données spécifiques, Air Pays de la Loire met en œuvre des systèmes automatisés de mesure de la concentration en particules selon la norme NF EN 16450, utilisant deux méthodes de mesure (microbalance oscillante ou atténuation par rayonnement bêta). Ces dernières sont installées dans des stations de mesure sur site, associées à des systèmes d’acquisition des données de mesure, qui les agrègent en moyennes trimestrielles. Ces données brutes sont ensuite transmises au serveur informatique central et évaluées à différents niveaux d’agrégation (validations techniques et environnementales). Les données trimestrielles validées sont ainsi agrégées en moyennes horaires, elles-mêmes agrégées en moyennes journalières, mensuelles ou annuelles.
La couche d’information produite est utilisable à une échelle allant de 1/250 000 à 1/10 000 et peut être classée par typologie de station :
- Poste de circulation : 1/10.000
- Station inférieure : 1/30.000 (urbain) à 1/250.000 (rural)
- Station industrielle : 1/100.000
Description des champs de la table de données.
- Département (/dept_name) : nom du département où se trouve la station de mesure (à partir des données IGN).
- Commune (/nom_com) : nom de la commune où est située la station de mesure (à partir des données IGN).
- Station ( / nom_station) : nom de la station de mesure déterminé par Air Pays de la Loire.
- Polluant (/nom_poll) : nom du polluant mesuré par la station de mesure.
- Valeur (/ value) : valeur de la mesure enregistrée pour un polluant à une station donnée et dans une métrique donnée.
- Unit (/unité) : unité de la valeur mesurée du polluant.
- Indicateur (/metrique) : niveau d’agrégation temporelle des données mesurées (heure, jour, mois, année).
- Date / Date-time ( / date_debut) : date de début du relevé de la mesure en heure locale (heure de métropole).
- insee_com : Code INSEE de la commune où est située la station de mesure (à partir des données IGN).
- code_station : Code unique de la station de mesure.
- typologie(influence) : Nature de la station de mesure déterminée par sa localisation et son influence en fonction du type de polluant qu’elle mesure.
- ID_poll_ue : Identifiant du polluant dans le système de référence européen.
- date_fin(/date_fin) : date de fin du rapport de mesure en heure locale (heure de métropole).
- statut_valid : validité de la mesure annotée, ‘t’ si la mesure est validée, ‘f’ si la mesure est invalidée.
- X_reglementaire : coordonnée x de l’emplacement de la station de mesure à Lambert 93 (EPSG : 2154).
- Y_reglementaire : coordonnée y de l’emplacement de la station de mesure à Lambert 93 (EPSG : 2154).
Description de la méthode utilisée.
Selon Air Pays de la Loire, la mesure de la qualité de l’air ambiant est réalisée selon les recommandations du référentiel professionnel du Laboratoire Central de Surveillance de la Qualité de l’Air (LCSQA), dans le respect des exigences réglementaires en vigueur.
Ces exigences couvrent l’ensemble de la chaîne de mesure, du point de vue des critères d’implantation des sites de mesure, du choix des méthodes d’analyse mises en œuvre, du suivi de la conformité métrologique du processus de mesure, de la validation et de l’agrégation des données de mesure.
Types de stations de mesure
En classant la variable typologie des stations (influence), la nature de la station de mesure est déterminée par sa localisation et son influence sur le type de polluant qu’elle mesure.
Les stations de mesure sont caractérisées en fonction de leur localisation et des sources d’émission auxquelles elles sont exposées. Il existe plusieurs types de localisation (rurale, urbaine et périurbaine) et d’influence (industrielle, de fond et de trafic). Les emplacements de fond correspondent à des zones où l’exposition de la population ou de l’environnement (végétation, écosystèmes naturels) à la pollution atmosphérique est moyenne et éloignée de toute source directe d’émissions.
Méthodologie – Mise en œuvre de l’analyse exploratoire des données (EDA)
Installation du paquet
Pour la mise en œuvre de l’analyse, nous avons choisi Python comme langage de programmation et Google COLAB comme environnement de travail, un outil en ligne créé pour le développement de projets de science des données, intégrant par défaut de nombreux paquets largement utilisés par les scientifiques des données.
- Matplotlib : génération de graphiques à partir de listes ou de tableaux.
- Numpy : logiciel de manipulation de vecteurs.
- Pandas : manipulation et analyse de tableaux et de séries temporelles.
- Scipy : outils et algorithmes mathématiques.
- Seaborn : visualisation de données statistiques.
- Plotly: analyse et visualisation de données en ligne.
# Importer les bibliothèques nécessaires
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import scipy.stats
import plotly
import plotly.graph_objects as go
Importation de données

Notre échantillon de données complet comprend un jeu de données au format .CSV pour chaque polluant téléchargé depuis la plateforme https://data.airpl.org/dataset/mesures, où il est nécessaire de filtrer la zone de la Loire-Atlantique, chaque polluant et d’indiquer les dates de début et de fin pendant 2023 sur une base journalière.
Afin de travailler avec la bibliothèque Pandas dans notre Notebook COLAB, nous importons nos fichiers .CSV et les convertissons en DataFrame pour une manipulation séparée en lui assignant un nom (ex : so2_df), et nous créerons également un dataframe final (ex : df_final) qui concaténera les données des quatre en une seule.
# Nous importons chaque fichier CSV et le convertissons en un cadre de données avec Pandas.
so2_df = pd.read_csv('so2_2023.csv', sep=';')
no2_df = pd.read_csv('no2_2023.csv', sep=';')
pm10_df = pd.read_csv('pm10_2023.csv', sep=';')
pm25_df = pd.read_csv('pm25_2023.csv', sep=';')
Préparation des données
Le nettoyage et l’adaptation des données pour l’analyse est une tâche obligatoire et peut-être le processus où nous apprenons le plus et obtenons la plus grande valeur de l’information pour atteindre nos objectifs.
La commande .info() de Pandas permet d’obtenir le nombre d’observations, ainsi que le nom, le nombre et le type de variables de chaque ensemble de données.
so2_df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3648 entries, 0 to 3647
Data columns (total 18 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 nom_dept 3648 non-null object
1 nom_com 3648 non-null object
2 insee_com 3648 non-null int64
3 nom_station 3648 non-null object
4 code_station (ue) 3648 non-null object
5 influence 3648 non-null object
6 nom_poll 3648 non-null object
7 id_poll_ue 3648 non-null int64
8 valeur 3616 non-null float64
9 unite 3648 non-null object
10 metrique 3648 non-null object
11 date_debut 3648 non-null object
12 date_fin 3648 non-null object
13 statut_valid 3647 non-null object
14 x_wgs84 3648 non-null float64
15 y_wgs84 3648 non-null float64
16 x_reglementaire 3648 non-null float64
17 y_reglementaire 3648 non-null float64
dtypes: float64(5), int64(2), object(11)
memory usage: 513.1+ KBPour l’exemple de l’ensemble de données so2_df, nous commençons avec 3648 observations et 18 variables disponibles pour démarrer notre analyse (n’oubliez pas qu’en parallèle, nous devons effectuer le même processus pour les trois autres ensembles de données : no2_df, pm10_df, pm25_df, et pm25_df)
Dictionnaire des variables

Après notre importation, nous avons 18 variables de différents types de données. Dix d’entre elles sont qualitatives et huit quantitatives. Il est important de noter que les variables temporelles : date_debut et date_fin sont de type Object, et nous les changerons plus tard en type DateTime pour visualiser et manipuler les données chronologiquement.
#Type de données variables
df_final.dtypes
output
nom_dept object
nom_com object
insee_com int64
nom_station object
code_station (ue) object
influence object
nom_poll object
id_poll_ue int64
valeur float64
unite object
metrique object
date_debut object
date_fin object
statut_valid object
x_wgs84 float64
y_wgs84 float64
x_reglementaire float64
y_reglementaire float64
dtype: objectEn préparant les données pour en évaluer la qualité, nous avons vérifié les données manquantes et la proportion de valeurs nulles pour chaque variable de notre ensemble.
# Quelle est la proportion de valeurs nulles par variable dans SO2 ?
(so2_df
.isnull()
.melt()
.pipe(
lambda df: (
sns.displot(
data=df,
y='variable',
hue='value',
multiple='fill',
aspect=2
)
)
)
)
# Vérification nombre de valeurs nulles
so2_df.isnull().sum()
nom_dept 0
nom_com 0
insee_com 0
nom_station 0
code_station (ue) 0
influence 0
nom_poll 0
id_poll_ue 0
valeur 39
unite 0
metrique 0
date_debut 0
date_fin 0
statut_valid 1
x_wgs84 0
y_wgs84 0
x_reglementaire 0
y_reglementaire 0
dtype: int64Nous pouvons également visualiser les valeurs nulles au sein de l’ensemble de données, validant ainsi le fait que ces valeurs ne sont pas concentrées dans une série d’observations spécifiques, mais dispersées dans l’ensemble de données.
# Afficher les valeurs nulles dans l'ensemble du jeu de données
df_final.isnull().transpose().pipe(lambda df: (sns.heatmap(data=df)))
Pour cet exemple de l’ensemble de données so2_df, nous avons 39 observations avec des valeurs nulles. Si nous analysons les informations que nous perdons en supprimant ou en imputant les données manquantes de chaque ensemble de données, nous pouvons conclure que ces valeurs nulles des quatre ensembles de données ne représentent pas un impact majeur sur notre ensemble de données si nous les imputons avec la moyenne de chaque variable. Cependant, il est toujours important d’évaluer quelle est la meilleure action pour ces données, car elles peuvent devenir des valeurs aberrantes importantes qui changent la direction de notre analyse ou de nos résultats. Je vous recommande cet article de Marta Castrillo qui m’a beaucoup aidé : How to identify and treat outliers with Python ?
📌 Remarque : N'oubliez pas d'effectuer le même processus pour l'ensemble de données de chaque polluant : so2_df, no2_df, pm10_df et pm25_df.
# Imputons la variable valuer avec la moyenne
so2_df['valeur'].fillna(so2_df['valeur'].mean(), inplace=True)
print("Missing values en valeur: " +
str(df_final['valeur'].isnull().sum()))
# Imputons la variable évaluateur avec la moyenne
so2_df['statut_valid'].fillna(so2_df['statut_valid'].mean(), inplace=True)
print("Missing values en statut_valid: " +
str(df_final['statut_valid'].isnull().sum()))
Missing values en valeur: 0
Missing values en statut_valid: 0📌 Remarque : si vous supprimez des données nulles, il est bon d'indiquer la quantité de données que vous perdez et la raison de votre décision. Dans ce cas, je n'ai pas supprimé mais imputé les données, c'est-à-dire que je les ai remplacées par la valeur moyenne de la variable "Valuer", qui est la variable principale de notre analyse.
Enfin, nous avons mentionné que nous devions changer le type de données des variables date_debut et date_fin en type datetime, pour cela nous utilisons à nouveau Pandas.
# Convertir les dates au format DateTime
so2_df['date_debut'] = pd.to_datetime(so2_df['date_debut'])
so2_df['date_fin'] = pd.to_datetime(so2_df['date_fin'])
no2_df['date_debut'] = pd.to_datetime(no2_df['date_debut'])
no2_df['date_fin'] = pd.to_datetime(no2_df['date_fin'])
pm10_df['date_debut'] = pd.to_datetime(pm10_df['date_debut'])
pm10_df['date_fin'] = pd.to_datetime(pm10_df['date_fin'])
pm25_df['date_debut'] = pd.to_datetime(pm25_df['date_debut'])
pm25_df['date_fin'] = pd.to_datetime(pm25_df['date_fin'])C’est une bonne pratique de toujours vérifier les changements, dans ce cas nous le faisons avec .dtypes.
so2_df.dtypes
nom_dept object
nom_com object
insee_com int64
nom_station object
code_station (ue) object
influence object
nom_poll object
id_poll_ue int64
valeur float64
unite object
metrique object
date_debut datetime64[ns]
date_fin datetime64[ns]
statut_valid object
x_wgs84 float64
y_wgs84 float64
x_reglementaire float64
y_reglementaire float64
dtype: objectAvant de passer au comptage et à la mise en rapport de nos ensembles de données, créons ou concaténons un cadre de données final ou général qui unifie les quatre polluants : df_final
# Concaténer les DataFrames en une seule DataFrame par ligne
contaminants = [no2_df, so2_df, pm10_df, pm25_df]
df_final = pd.concat(contaminants, axis=0, ignore_index=True)
df_final.head()
# Maintenant df_final contient les données des 4 polluants avec le même nombre de colonnes
Statistiques descriptives
Mesures de tendance centrale et mesures de dispersion générale de la variable à étudier.
De toutes les variables quantitatives, nous constatons que la principale à analyser est la valeur. Avec Numpy et la méthode .describe, nous pouvons visualiser les mesures de tendance centrale.
# Mesures de tendance centrale, uniquement pour les variables numériques
df_final.describe(include=[np.number])
Cette variable « Valeur » indique l’indice de pollution à calculer en tant que variable quantitative.
Les variables centrales du dataframe df_final sont définies comme suit : la moyenne (8,485196 µg/m3) et la médiane (6,4 µg/m3).
En ce qui concerne les indicateurs de dispersion, nous utiliserons le BoxPlot pour vérifier le niveau de dispersion entre la moyenne et la médiane.

Nous constatons que le box plot de la variable « valeur » a sa plus grande distribution de données entre 2,2 ~ 12, se présentant comme asymétrique vers la droite, assez dispersé avec une large gamme parce qu’il y a des données qui atteignent un maximum de 75.
Statistiques descriptives univariées
Nous allons ici extraire les variables qualitatives de notre dataframe df_final :
# Uniquement les variables catégorielles
df_final.describe(include=object)
Pour étudier les variables qualitatives, nous commencerons par visualiser la répartition par commune en Loire-Atlantique.

Ainsi, 23% des mesures sont effectuées sur la commune de Donges, suivie de Nantes (20%) et de Saint-Nazaire (12%). Si l’on comptabilise les observations par commune (nom_com), on constate leur répartition, avec Donges et Nantes comme principaux sites de mesure. En effet, Donges est la région qui compte le plus de stations de mesure de la qualité de l’air (4 stations), suivie de Nantes (3 stations), ce qui explique qu’elle compte presque deux fois plus d’observations que Saint-Nazaire qui arrive en troisième position (2 stations).

En analysant la carte de la Loire-Atlantique, on constate que la région de Donges a un fort impact industriel en raison de la présence de la raffinerie Total Energies, où une fuite d’essence s’est produite à partir d’un réservoir de stockage le 21 décembre 2022, ce qui explique que plusieurs mesures de surveillance et de contrôle de la qualité de l’air aient été mises en place dans la région.

df_final.value_counts('nom_com', sort=True)
nom_com
Donges 3646
Nantes 3249
Saint-Nazaire 1841
Saint-Etienne-De-Montluc 1461
Montoir-De-Bretagne 1460
Frossay 1318
Bouguenais 1095
Rezé 787
Paimbœuf 365
Trignac 365
Savenay 364
dtype: int64
Quelle est la commune où la concentration moyenne de polluants est la plus élevée ?
Il est important de noter qu’en visualisant la concentration des polluants par commune, il n’y a pas de corrélation entre la commune ayant le plus d’observations (Donges) et la commune ayant les indices de concentration les plus élevés, où dans notre cas c’est Rezé, suivie de Nantes, qui occupent les premières places.
avg_concentration_by_comuna = df_final.groupby('nom_com')['valeur'].mean().sort_values(ascending=False)
plt.figure(figsize=(12, 6))
avg_concentration_by_comuna.plot(kind='bar', color='skyblue', hue='nom_com')
plt.title('Average Concentration per Commune')
plt.xlabel('Commune')
plt.ylabel('Average Concentration')
plt.show()
avg_concentration_by_comuna.head()
nom_com
Rezé 13.108880
Nantes 13.063650
Bouguenais 11.697341
Trignac 8.307994
Montoir-De-Bretagne 7.894922
Name: valeur, dtype: float64# Analyse de la concentration des polluants par commune en df_final
plt.figure(figsize=(15, 6))
sns.boxplot(x="nom_com", y="valeur", data=df_final)
plt.title("Concentration of pollutants by commune")
plt.xticks(rotation=45, ha="right")
plt.show()
Il est maintenant temps d’analyser la distribution par « typologie » : (influence), l’une des catégories les plus importantes de l’ensemble des données (df_final), qui nous permet d’établir les pourcentages de l’activité humaine influençant la pollution dans la région, en fonction du nombre d’observations.

On constate que 63% des mesures effectuées ont une influence « industrielle« . Si l’on met en relation la typologie avec la mesure par polluant (nom_poll), on confirme l’origine de celle-ci.

Combinaison de variables : statistiques descriptives bivariées
La combinaison de variables permet de déterminer si une variable en influence une autre.
La variable qualitative « valeur » étant celle que nous voulons étudier, nous allons faire des statistiques bivariées en nous concentrant sur cette variable.

Lors des études univariées, nous avons réalisé un box plot sur la valeur du polluant. Il semble logique d’utiliser ce diagramme en ajoutant une variable qualitative pour effectuer une comparaison de la dispersion.
Nous avons remarqué que les stations de background naturel et les stations industrielles ont une dispersion similaire avec des quantiles, des médianes et des maxima à des niveaux faibles, tandis que les stations spécifiques et les stations de trafic ont des indicateurs de dispersion plus élevés. Une fois encore, la répartition des stations en fonction de leur influence ou de leur origine nous montre que l' »industrie » a le plus grand nombre d’observations dans notre ensemble de données, mais que c’est le « trafic » dont les valeurs montrent que c’est l’activité humaine qui a le plus d’impact sur la pollution.
Par conséquent, nous pouvons déduire la typologie qui influence notamment le taux de ses valeurs polluantes dans chaque lieu de la région : les environnements qui montrent un volume élevé de « Trafic » ont des niveaux plus élevés de valeurs polluantes et il serait donc conseillé de les éviter afin de vivre ou de rester près de ces points.
Les initiatives telles que NAOAIR deviennent des solutions importantes pour nous informer en temps réel sur la qualité de l’air, que nous choisissions de voyager ou de faire du sport.

Depuis des années, la Commission européenne souligne que la pollution de l’environnement est trop élevée et que les substances nocives dépassent les limites légales. Ce reportage d’EuroNews étudie l’impact de cette situation dans certaines villes françaises.
Les polluants les plus préoccupants :

La concentration moyenne des polluants montre que les PM10 ☣️ sont les plus répandues et donc les plus préoccupantes pour la santé des habitants de la région.
Relation entre la concentration de polluants et l’activité humaine par commune :

Variation temporelle de la concentration de polluants par polluant :

Calculer les jours de mesure et les stations présentant les valeurs de pollution les plus élevées par polluant :
Les stations de surveillance enregistrent des niveaux constamment élevés :

# Calculer le nombre de jours de mesure
num_days = df_final['date_debut'].nunique()
print(f "Nombre de jours de mesure : {num_jours}")
# Identifier les stations avec le plus de valeurs de pollution
stations_avec_le_plus_de_pollution = df_final.groupby('nom_station')['valeur'].mean().sort_values(ascending=False).head(5)
print("Stations avec le plus de valeurs de contamination :")
print(stations_avec_le_plus_de_pollution)
# Afficher les résultats
plt.figure(figsize=(12, 6))
sns.barplot(x=stations_avec_le_plus_de_pollution.index, y=stations_avec_le_plus_de_pollution.valeurs, palette="viridis")
plt.title("Stations avec les valeurs de pollution les plus élevées")
plt.xlabel("Nom de la station")
plt.ylabel("Concentration moyenne de polluants")
plt.xticks(rotation=45, ha="right")
plt.show()
Nombre de jours de mesure : 365
Stations avec plus de valeurs de pollution :
nom_station
FRERES GONCOURT 17.466060
TRENTEMOULT 13.108880
LES COUETS 11.697341
CIM BOUTEILLERIE 11.027805
LA CHAUVINIERE 10.841820
Nom : valeur, dtype : float64
<ipython-input-447-77ba1b50069e>:12: FutureWarning:

Tendance générale de la concentration de polluants au cours de l’année écoulée :

# Trouver le jour le plus pollué et les saisons associées
most_polluted_day = df_final.loc[df_final.groupby('date_debut')['valeur'].idxmax()]
most_polluted_day_sorted = most_polluted_day.sort_values(by='valeur', ascending=False)
Jour le plus pollué de l'année (de la valeur la plus élevée à la valeur la plus basse) :
date_debut nom_station valeur
9362 2023-09-06 CIM BOUTEILLERIE 75.0
3855 2023-02-14 FRERES GONCOURT 70.0
3907 2023-02-10 FRERES GONCOURT 68.0
11651 2023-02-09 LES COUETS 66.0
1379 2023-09-08 FRERES GONCOURT 65.0
... ... ... ...
11078 2023-04-02 TRENTEMOULT 11.0
9473 2023-08-27 TRENTEMOULT 10.0
1667 2023-08-15 FRERES GONCOURT 9.4
10692 2023-05-08 TRENTEMOULT 9.4
10702 2023-05-07 TRENTEMOULT 7.2
# Si vous souhaitez également afficher les valeurs de polluants de ce jour pour toutes les stations
most_polluted_day_all_stations = df_final[df_final['date_debut'] == most_polluted_day_sorted.iloc[0]['date_debut']]
most_polluted_day_all_stations_sorted = most_polluted_day_all_stations.sort_values(by='valeur', ascending=False)Valeurs des polluants pour ce jour-là dans toutes les stations (classées de la valeur la plus élevée à la valeur la plus faible) :
date_debut nom_station valeur nom_poll
9362 2023-09-06 CIM BOUTEILLERIE 75.000000 PM10
9359 2023-09-06 LA CHAUVINIERE 64.000000 PM10
9356 2023-09-06 LA MEGRETAIS 62.000000 PM10
9363 2023-09-06 TRENTEMOULT 62.000000 PM10
9358 2023-09-06 SAINT ETIENNE DE MONTLUC 61.000000 PM10
9365 2023-09-06 CAMEE 55.000000 PM10
9357 2023-09-06 FROSSAY 53.000000 PM10
9361 2023-09-06 PARSCAU DU PLESSIS 50.000000 PM10
9360 2023-09-06 LEON BLUM 48.000000 PM10
1403 2023-09-06 FRERES GONCOURT 39.000000 NO2
13408 2023-09-06 LEON BLUM 23.000000 PM2.5
13414 2023-09-06 FRERES GONCOURT 23.000000 PM2.5
13410 2023-09-06 CIM BOUTEILLERIE 22.000000 PM2.5
1401 2023-09-06 LES COUETS 22.000000 NO2
13407 2023-09-06 LA CHAUVINIERE 20.000000 PM2.5
13406 2023-09-06 SAINT ETIENNE DE MONTLUC 19.000000 PM2.5
1399 2023-09-06 PARC PAYSAGER 19.000000 NO2
13412 2023-09-06 LES COUETS 18.000000 PM2.5
13405 2023-09-06 FROSSAY 18.000000 PM2.5
13404 2023-09-06 LA MEGRETAIS 18.000000 PM2.5
1402 2023-09-06 CAMEE 18.000000 NO2
1395 2023-09-06 JULES VERNE 18.000000 NO2
1397 2023-09-06 LEON BLUM 17.000000 NO2
13413 2023-09-06 CAMEE 17.000000 PM2.5
13411 2023-09-06 TRENTEMOULT 17.000000 PM2.5
1396 2023-09-06 LA CHAUVINIERE 16.000000 NO2
13409 2023-09-06 PARSCAU DU PLESSIS 16.000000 PM2.5
1392 2023-09-06 LA MEGRETAIS 16.000000 NO2
1398 2023-09-06 PARSCAU DU PLESSIS 16.000000 NO2
1400 2023-09-06 CIM BOUTEILLERIE 14.000000 NO2
9364 2023-09-06 LES COUETS 8.448881 PM10
9366 2023-09-06 FRERES GONCOURT 8.448881 PM10
1393 2023-09-06 FROSSAY 8.300000 NO2
1394 2023-09-06 SAINT ETIENNE DE MONTLUC 7.000000 NO2
5585 2023-09-06 LA MEGRETAIS 3.500000 SO2
5592 2023-09-06 PARC PAYSAGER 1.700000 SO2
5590 2023-09-06 CUTULLIC2 1.600000 SO2
5586 2023-09-06 PASTEUR 0.650000 SO2
5584 2023-09-06 AMPERE 0.440000 SO2
5591 2023-09-06 PARSCAU DU PLESSIS 0.280000 SO2
5587 2023-09-06 FROSSAY 0.240000 SO2
5593 2023-09-06 CAMEE 0.070000 SO2
5589 2023-09-06 SAINT ETIENNE DE MONTLUC 0.000000 SO2
5588 2023-09-06 SAVENAY 0.000000 SO2Les jours où les niveaux de pollution ont été les plus élevés en 2023 ont été la mi-février et la première semaine de septembre, qui correspondent aux jours les plus froids de l’hiver et à la semaine de la rentrée scolaire et des vacances de fin d’année.
Variation de la concentration au cours des différentes saisons de l’année :

Plus de questions 🤔
Voici quelques questions supplémentaires qui pourraient nous aider à explorer les corrélations, les causalités ou les différences qui peuvent être liées aux problèmes sociaux liés aux émissions de polluants :
- Existe-t-il une corrélation entre la concentration de polluants et les taux de maladies respiratoires dans la population de chaque commune ?
- Existe-t-il une relation entre l’activité industrielle dans une commune et les niveaux de pollution de l’air dans cette zone ?
- Existe-t-il une différence significative de la qualité de l’air entre les zones urbaines et rurales ?
- Comment les conditions météorologiques, telles que la température et la vitesse du vent, affectent-elles la dispersion des polluants ?
- Existe-t-il des preuves de disparités socio-économiques dans l’exposition aux polluants, et quel est le lien avec les décisions d’urbanisme ?
- La présence d’espaces verts ou de parcs dans une commune est-elle corrélée à des niveaux plus faibles de polluants ?
- La mise en œuvre de politiques environnementales ou de restrictions réglementaires a-t-elle eu un impact observable sur la réduction des émissions de polluants ?
- Peut-on établir une relation entre la mobilité urbaine (utilisation des transports publics, véhicules électriques, etc.) et la qualité de l’air ?
- Comment la perception de la qualité de l’air par le public varie-t-elle par rapport aux données objectives sur la pollution ?
- Existe-t-il des différences dans les niveaux de polluants entre les jours de semaine et les week-ends, et comment cela peut-il être lié aux schémas d’activité humaine ?
Ces questions permettent de mieux comprendre les facteurs sociaux, économiques et environnementaux qui contribuent aux problèmes liés aux émissions de polluants et à la qualité de l’air.
L’analyse révèle des points chauds de pollution dans certaines communes, soulignant la nécessité d’interventions spécifiques. Des corrélations entre l’activité industrielle, les conditions météorologiques et les concentrations de polluants ont été identifiées. La mise en œuvre de politiques environnementales et la promotion de la mobilité durable pourraient atténuer les effets négatifs sur la qualité de l’air. En outre, les disparités socio-économiques dans l’exposition aux polluants soulignent l’importance de traiter les problèmes environnementaux dans une perspective équitable et axée sur la santé publique.
Ce projet a été entrepris dans le but de comprendre le problème de la pollution environnementale et de mettre en pratique les connaissances acquises dans le domaine de la science des données. Il va sans dire qu’il s’agit d’un exercice de jugement personnel et de valeur, et qu’il sera sûrement plein de corrections que j’espère pouvoir continuer à apporter grâce aux commentaires de chacun. 😊
Dashboard interactive en Looker Studio 👇
https://lookerstudio.google.com/reporting/4534372d-c6af-4361-ad26-e555bfe7c05c
Sources:
https://data.airpl.org/dataset/mesures
This EuroNews report investigates their impact in some French cities.
How to identify and treat outliers with Python ?
#qualityair #dataanalyst #LinkedInAnalysis #DataScience #EnvironmentalSustainability #pollution #climatechange #environnement #nantes #paydelaloire #loireatlantique #climat